캣툴을 활용한 번역 파일 만들기
이번 장에서는 실제로 캣툴을 활용하여 프로젝트 파일을 생성하고 비번역 처리까지 완료하는 예제를 보여드립니다. 예제는 단일 언어(영어 > 한글) 프로젝트와 다국어(한국어 > 영어, 일본어, 중국어) 프로젝트를 만드는 것으로 나누어 설명하겠으며 사용하는 캣툴은 memoQ입니다. memoQ는 가장 대중화된 캣툴이라 할 수 있는 Trados Studio보다는 사용자 수가 적은 편이지만 상대적으로 저렴한 가격과 사용자의 편의를 고려한 내부 기능으로 인해 게임 현지화에서는 표준으로 자리매김해 가고 있습니다. 따라서 번역용 프로젝트 파일 생성 관련 설명은 memoQ를 기준으로 말씀드리겠습니다.
단일 언어 프로젝트 생성
단일 언어 프로젝트는 영어에서 한글로 번역하는 것을 기준으로 예제를 보여드리겠습니다. 예제에 사용될 파일은 설명을 위해 새로 작성한 txt 파일(영한프로젝트샘플.txt )입니다. 설명을 목적으로 임의 작성한 파일이지만 실제 게임 번역용으로 제공되는 소스와 유사한 구조로 작성했습니다.
번역용 파일 분석
번역해야 할 내용은 게임 설치나 충돌에 대한 문제 해결 방법을 안내하는 것으로 판단됩니다. 웹에서 주로 사용하는 html 태그를 제외하면 첫 문장의 시작을 나타내는 숫자 외에는 큰 특이점은 없어 보입니다. 탭(tab)이나 콤마( , ) 등의 기호로 구분되는 값이 없기 때문에 일반적인 txt 파일로 간주하고 파일 준비 작업을 진행해도 문제 없을 것 같습니다. 내용 구성상 네 자리 숫자 다음에 나오는 내용이 제목, 그 다음에 html 태그와 함께 나오는 부분이 제목에 대한 설명으로 보입니다.
memoQ를 실행하고 [Project] > [New Project]를 선택합니다.

새롭게 팝업된 [New memoQ project] 창에서 다음 사항을 입력합니다.
[옵션 설명]
Name: 전체 프로젝트의 이름을 입력합니다. 프로젝트 이름은 누가 보더라도 직관적으로 이해할 수 있게 작성하는 것이 좋습니다. 예를 들어 A게임사에서 개발한 B게임의 영한 프로젝트라고 가정한다면 [Agames_Bgame_ENtoKO]와 같은 형태로 작성하는 것이 좋습니다. 이렇게 하면 프로젝트 이름만 봐도 고객사, 게임 프로젝트명, 언어쌍(language pair) 정보까지 바로 알 수 있습니다.
Source language: 번역의 기준이 되는 언어를 선택합니다. 영한 번역에 대한 프로젝트를 만들기로 했으므로 소스 언어(Source language)는 영어입니다. 다만, memoQ 옵션 중 영어 관련 옵션은 영국, 미국, 호주, 캐나다 등 상당히 다양합니다. 특정 국가를 기준으로 작성된 원본일 경우에는 해당 국가를 선택하는 것이 좋으나, 그런 목적으로 작성된 원본이 아니라면 아무런 옵션이 붙지 않은 [English] 선택을 권장합니다. 다른 작업자와의 혼선을 줄이기 위한 것입니다.
Target language: 번역하고자 하는 언어를 선택합니다. 이 프로젝트에서는 한국어로 번역할 계획이므로 [Korean]을 선택합니다.
Project: 세부 프로젝트 이름입니다. 상단에서 전체 프로젝트 이름을 지정했기 때문에 이 부분은 기입하지 않아도 상관 없습니다. 특별한 구분이 필요 없을 때는 생략하거나 전체 상단의 프로젝트 이름과 동일하게 구성해 주면 됩니다.
나머지 정보는 비워두거나 기본값(default)으로 두고 [Next]를 클릭합니다.
새로 열린 이 창은 번역할 파일을 업로드하는 창입니다. 본 문서와 함께 제공하는 영한프로젝트샘플.txt 파일을 활용해서 설명을 계속하겠습니다. [Import with options…] 옵션을 사용하여 영한프로젝트샘플.txt 파일을 업로드합니다.
업로드 창이 새로 생성되면서 업로드할 때 선택할 수 있는 옵션이 나타납니다. 여기서 중요한 것은 [Filter & configuration] 옵션입니다. 대부분은 CAT Tool이 자동 감지해서 해당 파일 형식에 가장 알맞은 필터를 선택해줍니다. 적절한 필터로 선택되지 않았다면 사용자가 직접 필터를 선택해줄 수도 있습니다. 샘플로 사용하는 파일 형식인 .txt에는 Plain text filter가 가장 적절하므로 다른 옵션 변경 없이 그대로 사용하겠습니다. 옵션 변경이 필요하다면 아래 그림처럼 파일을 체크하고 [Change filter & configuration) 옵션을 사용합니다.
신규 문서에 대한 하단 4개 옵션 중 [Record version history] 옵션만 선택해서 사용하겠습니다. 옵션 설정이 끝났다면 [OK]를 클릭하여 창을 닫습니다.
파일 업로드를 마치고 나면 해당 파일의 이름 및 가져온 경로(Import path), 내보낼 경로(Export path) 정보가 표시됩니다. 이 경로는 항상 동일하게 설정됩니다. 파일 번역을 완료하고 cleanup을 하면 동일한 경로에 번역된 파일이 저장되는 것입니다. [Next]를 클릭하여 TM 설정 창으로 이동합니다.
TM 설정 창에는 기존에 사용하던 TM이 모두 표시됩니다. 기존 TM을 활용할 경우에는 이 중 하나를 선택하거나 컴퓨터에 저장되어 있는 TM 파일을 불러와서 사용합니다. 본 예제에서는 새로 작성해 보겠습니다. [Create/use new]를 클릭하여 TM 생성 창을 엽니다.
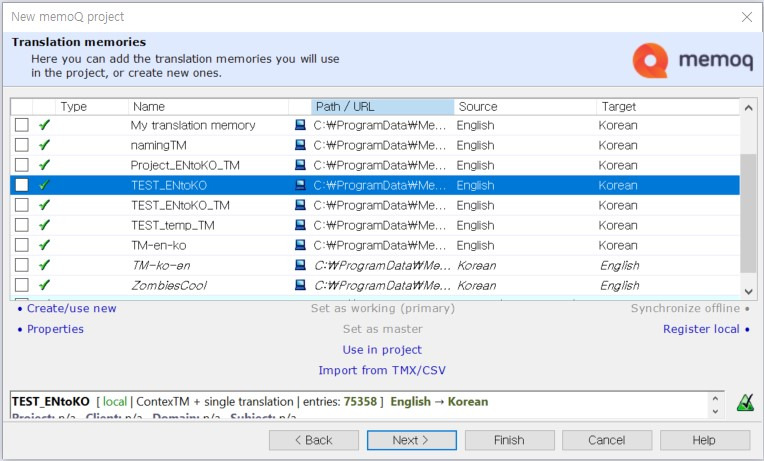
[옵션 설명]
Create/use new: TM 파일을 새로 생성합니다. 기존 TM을 사용할 수 없거나 완전히 새로운 프로젝트를 시작할 때 사용하는 옵션입니다.
Register local: 컴퓨터에서 기존 TM이 저장된 경로를 찾아 등록합니다. memoQ에서 사용하는 TM 파일의 확장자는 .mtm(TB의 경우 .mtb)입니다. 다른 CAT Tool에서 사용하던 파일을 .tmx나 .csv 형식으로 보유하고 있다면 이 옵션은 사용할 수 없습니다.
Properties: 기존 TM 중 선택한 TM의 속성을 확인합니다.
Use in project: 기존 TM 중 선택한 TM을 업무용 TM(Working TM)으로 등록합니다.
Import from TMX/CSV: CAT Tool에서 .tmx 또는 .csv 형식으로 저장해 놓은 TM을 가져옵니다.
TM을 새로 생성할 때는 TM 이름 또한 사용할 프로젝트명과 유사하게 만들어 주는 것이 좋습니다. 기존 옵션은 수정하지 않고 그대로 [OK]를 클릭하여 창을 닫습니다.
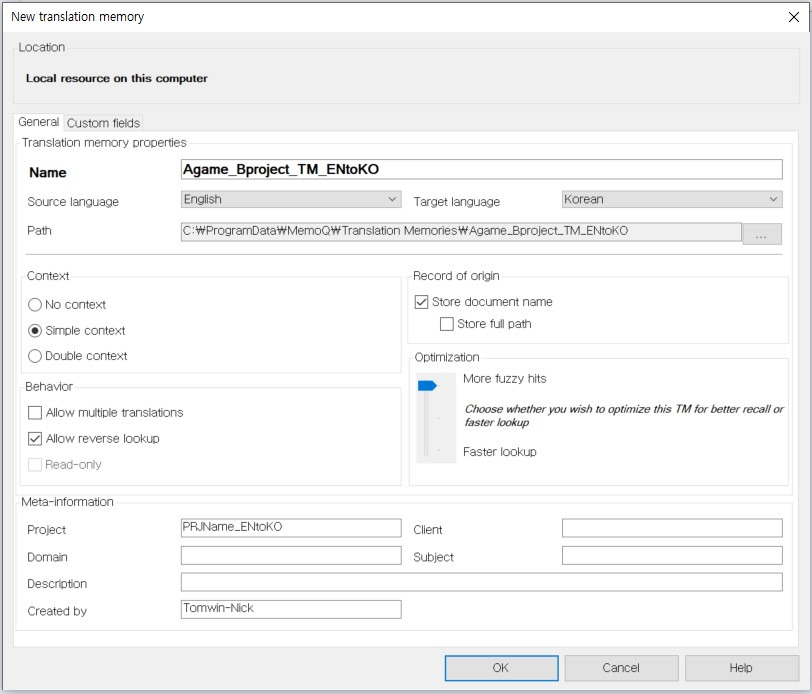
[옵션 설명]
Context: TM에 내용을 저장할 때 자동으로 설정하는 문맥(context)에 대한 옵션입니다.
No context: 문맥과 상관 없이 가장 일치도가 높은 세그먼트를 우선 검색합니다.
Simple context: TM에 저장된 순서를 기준으로 앞뒤 문맥을 파악하여 해당 문맥의 일치도까지 고려한 세그먼트를 우선 검색합니다.
Double context: [Simple context]에서 고려한 문맥 정보 외에 각 세그먼트의 ID까지 확인하여 해당 ID까지 일치하는 세그먼트를 우선 검색합니다.
Record of origin: 원본에 대한 기록 저장 여부를 결정하는 옵션입니다.
Store document name: 저장되는 각 세그먼트에 원본 파일의 이름 정보를 저장합니다.
Store full path: 컴퓨터에 저장된 원본 파일의 위치 정보를 저장합니다.
Behavior: TM의 작동 방식에 대한 옵션입니다.
Allow multiple translations: 다중 번역을 허용합니다. 동일한 소스 언어에 대해 여러 버전의 타겟 언어를 저장할 수 있게 해줍니다. TM의 가장 기본이 되는 원칙이라 할 수 있는 “소스 언어와 타겟 언어의 1대1 대응”이라는 전제를 거스르는 옵션이기 때문에 사용에 신중을 기하는 것이 좋습니다. 특수한 경우가 아니면 사용하지 않습니다.
Allow reverse lookup: 타겟 언어로 검색을 허용합니다. 보통 TM에 저장한 세그먼트는 소스 언어를 기준으로만 검색이 가능하지만 이 옵션을 사용하면 타겟 언어에서도 검색이 가능합니다. TM의 활용도를 많이 끌어올릴 수 있는 옵션이니 반드시 선택합니다.
Read-only: 새로 번역한 내용을 TM에 저장할 수 없으며 참고용으로 확인만 가능하게 만드는 옵션입니다.
Optimization: TM 내용을 검색할 때 퍼지 매치(fuzzy match)를 더 많이 찾아보거나 검색 속도를 빠르게 만드는 방향 중 하나를 선택하는 옵션입니다. TM의 내용이 너무 많아 검색할 때마다 너무 시간이 오래 걸린다면 검색이 빠른 쪽으로 최적화하는 것이 좋습니다.
창을 닫음과 동시에 새로 생성한 TM이 TM 창의 최상단에 위치합니다. 왼쪽의 확인란이 체크되어 있으면 완료된 것입니다. 다시 [Next]를 클릭해서 텀베이스(Termbase) 설정으로 이동하겠습니다.
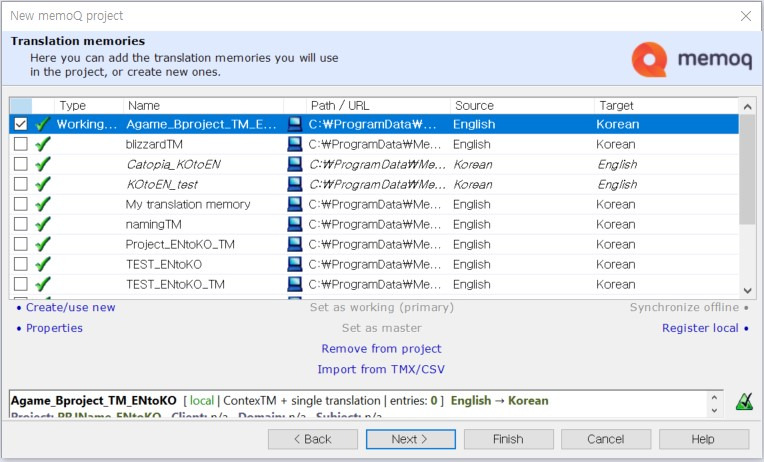
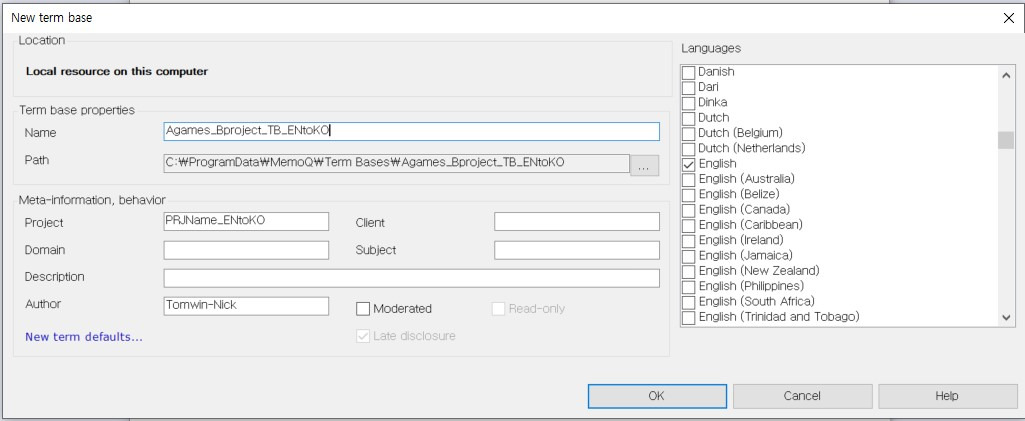
텀베이스 선택 화면은 TM과 동일하므로 별도의 옵션 관련 설명은 생략하겠습니다. 본 예제에서는 [Create/use new]를 선택하여 신규 텀베이스를 생성하겠습니다.
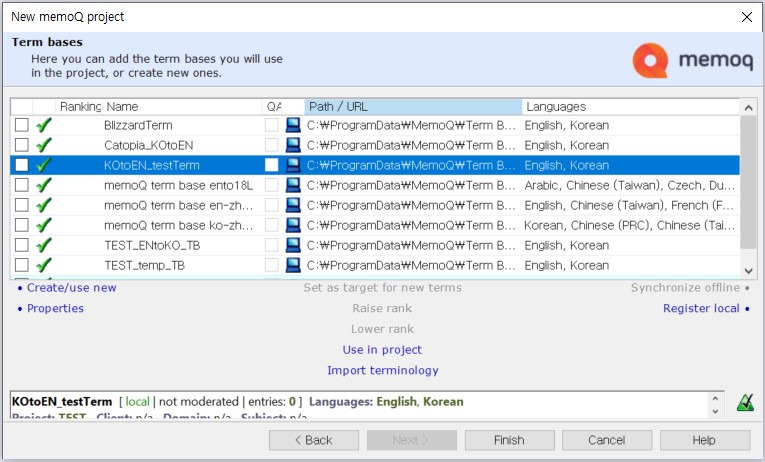
텀베이스를 새로 만들 때는 오른쪽의 [Languages] 옵션을 잘 살펴봐야 합니다. 기본값으로 처음 설정한 소스 언어(English)와 타겟 언어(Korean)가 체크되어 있지만 한번 더 확실하게 확인해 주는 게 좋습니다. 확인을 마쳤다면 [OK]를 클릭하여 텀베이스를 생성하고 마지막으로 [Finish]를 클릭하여 프로젝트를 생성합니다.
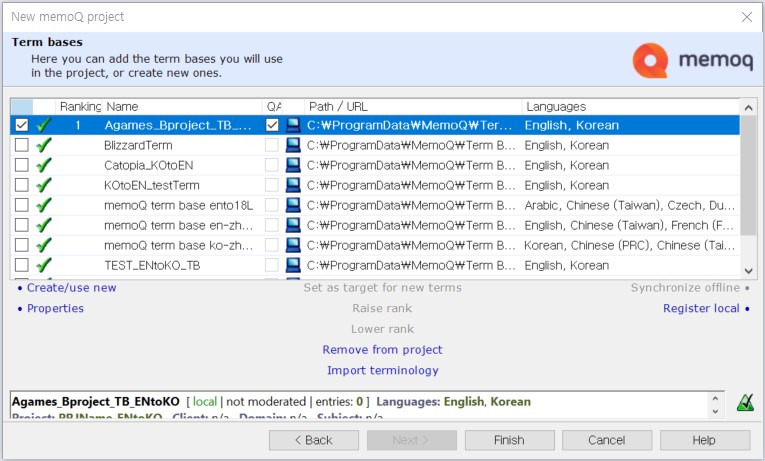
이로써 신규 프로젝트 생성을 마쳤습니다. 이제 업로드된 번역용 파일을 열어 비번역 대상에 대한 비번역 처리를 진행하겠습니다. 파일은 두 번 클릭하면 열립니다.
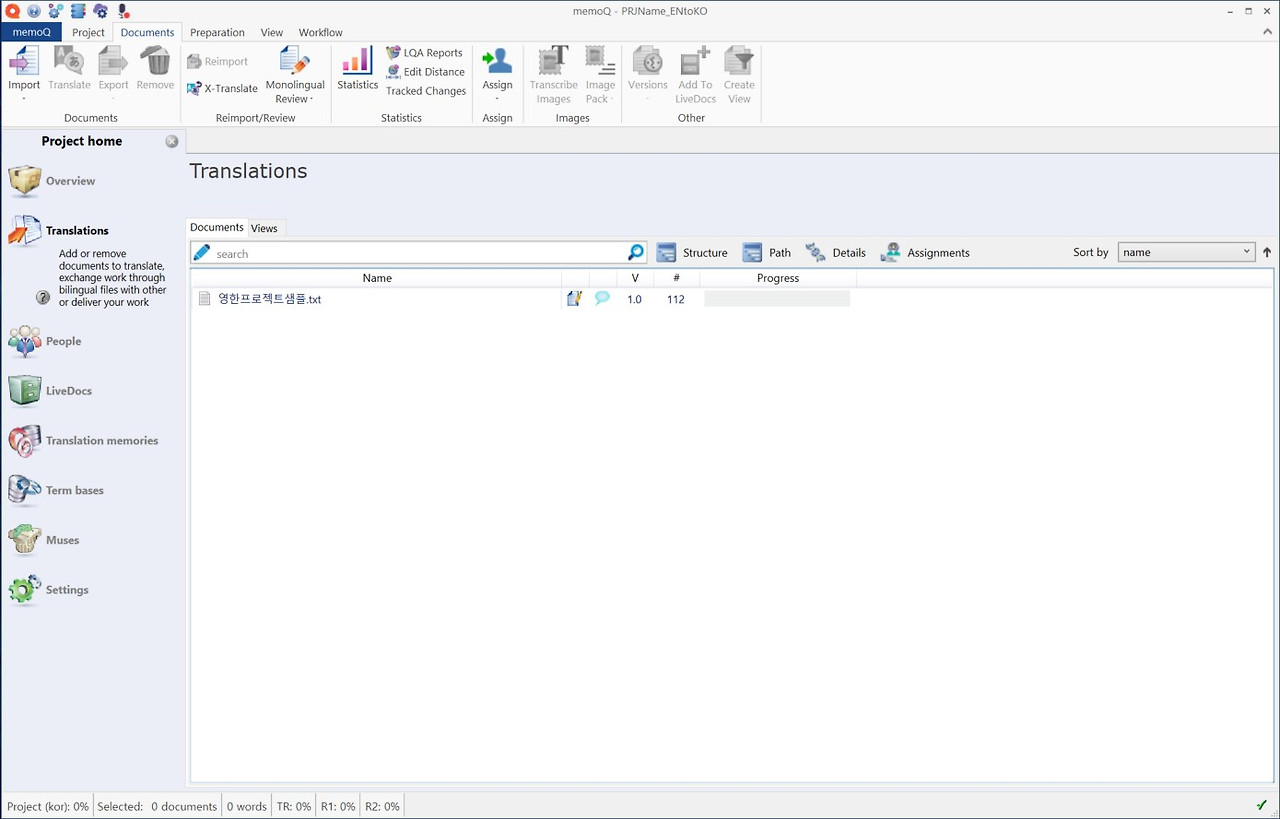
번역할 파일을 열어보면 비번역 처리해야 할 대상이 많이 보입니다.

각 열별로 비번역 처리해야 할 대상을 빨간색으로 표시해 보았습니다.
1번열: 없음
2번열: 없음
3번열
<p>Visit the Dragon site</a> for information on how to sign up for a chance to get beta access.</p>
4번열: 없음
5번열: 없음
6번열
<p>If there are issues preventing you from installing this game, follow the steps on the Unable to Install Dragon</a> article to troubleshoot before you report us.</p>
7번열: 없음
8번열: 없음
9번열
<p>Our Dragon Issues and Crashes</a> article has helpful steps to help you resolve any crashing issues in the game.</p>
10번열: 없음
11번열: 없음
12번열
<p>Check the Dragon Twitter</a> feed for any known issues before following the steps on the Dragon Connection Issues</a> support article to help you resolve any connection issues.</p>
가장 먼저 해야 할 일은 비번역 처리 대상들의 패턴을 파악하는 일입니다. 앞서 학습했던 정규표현식을 적용하기 위해서는 대상을 특정지을 수 있는 특징을 찾아내야 합니다. 비번역 처리 대상을 자세히 보면 모든 내용이 왼쪽 꺾쇠(<)로 시작해서 오른쪽 꺾쇠(>)로 끝난다는 점이 보입니다. 바로 html 태그의 특징입니다. 앞서 학습한 정규표현식의 게으른 수량자(lazy quantifier)를 활용하여 다음과 같이 식을 작성하면 쉽게 비번역 처리를 완료할 수 있을 것 같습니다.
[사용할 정규표현식]
<.*?>
이제 정규표현식을 적용할 문장 중 몇 개를 정규식 연습 사이트(https://regexr.com/)에 복사하여 실제로 잘 적용되는지 마지막 확인을 하겠습니다.
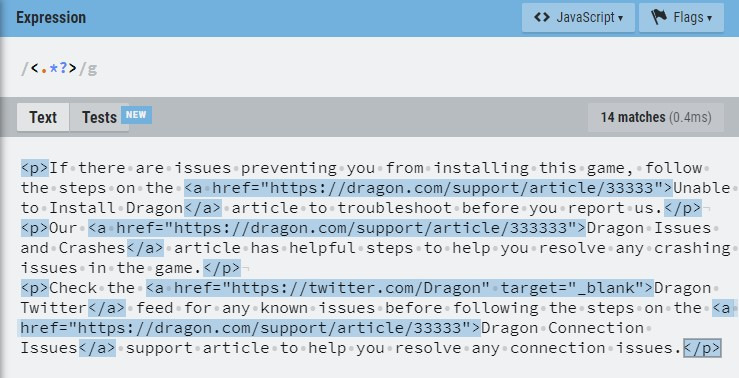
예상했던 대로 태그에 해당되는 부분만 모두 선택되는 것을 확인했습니다. 이제 이 식을 memoQ에 있는 실제 파일에 적용해 보겠습니다. 파일이 열려 있는 상태에서 메뉴 상단에 있는 [Preparation] > [Regex Tagger] 메뉴를 선택합니다.
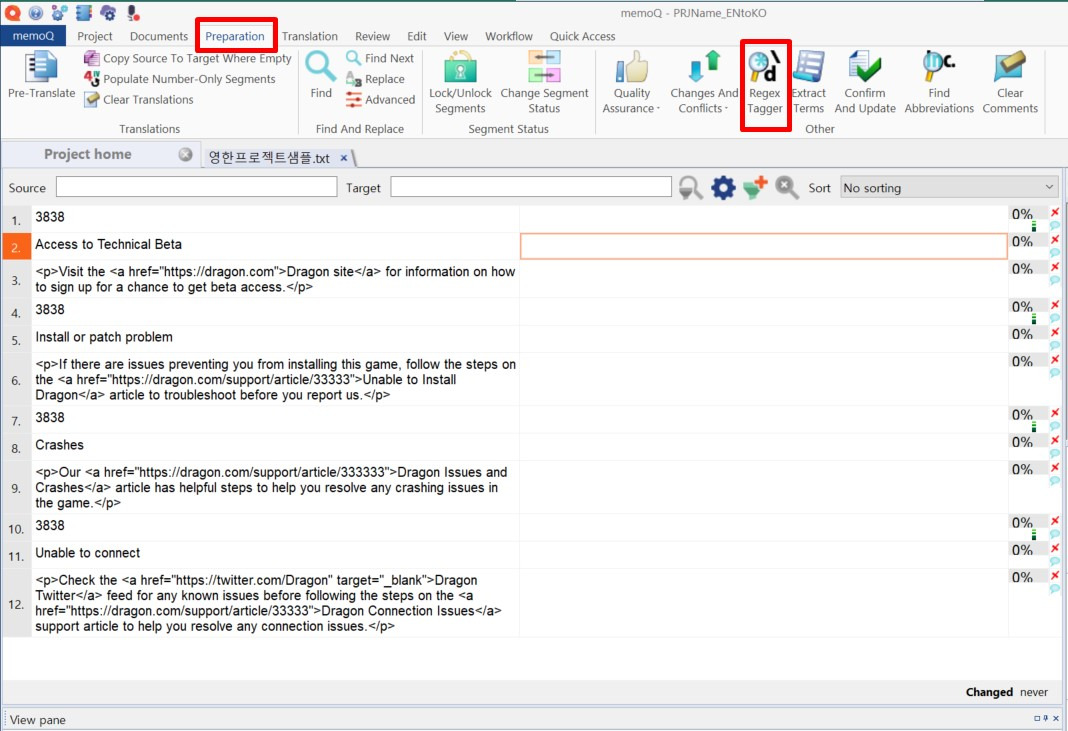
[Regex Tagger]를 클릭하면 표시되는 Tag current document 창을 이용해서 작성한 정규표현식을 적용합니다. [Regular expression]이라고 써 있는 오른쪽의 빈 칸에 정규표현식을 입력하고 바로 아래에 있는 [Add]를 클릭해서 규칙을 저장합니다.
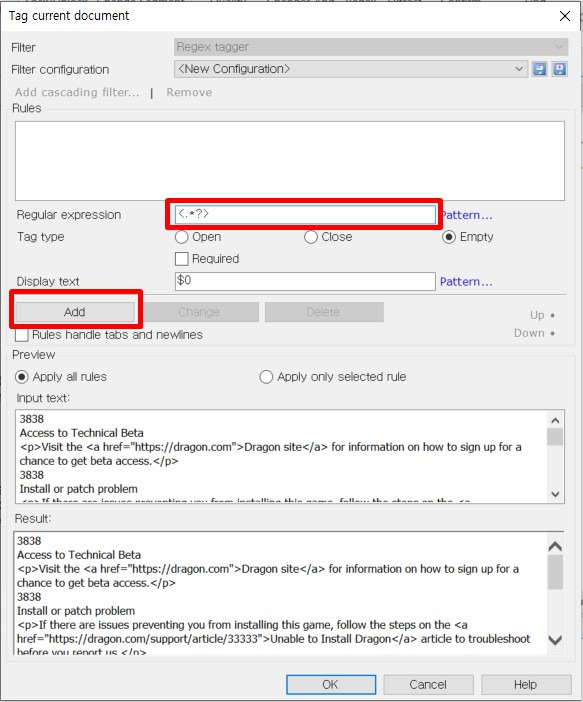
규칙을 저장하고 나면 아래 그림처럼 [Rules] 란에 저장된 규칙이 표시되고 제일 아래 칸에서는 해당 규칙을 적용했을 때 텍스트에 어떤 부분이 선택되는지를 확인할 수 있습니다.
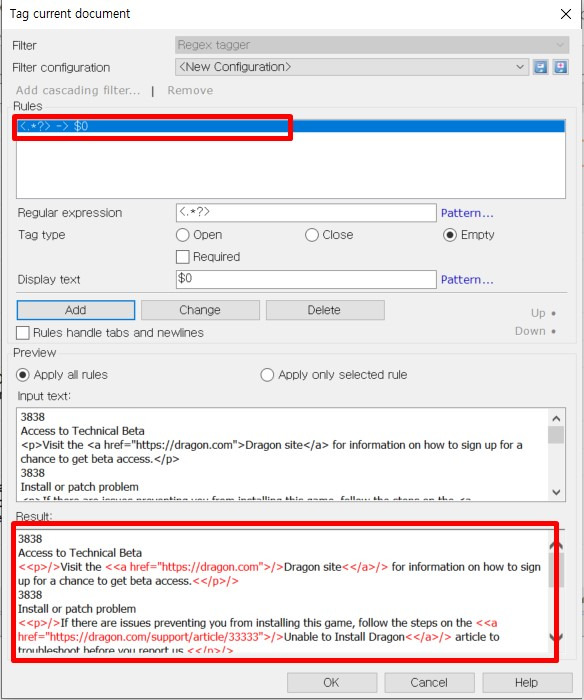
예상 결과 부분을 확인해서 문제가 없다면 [OK]를 클릭해서 적용합니다. 적용한 결과물은 아래와 같습니다.
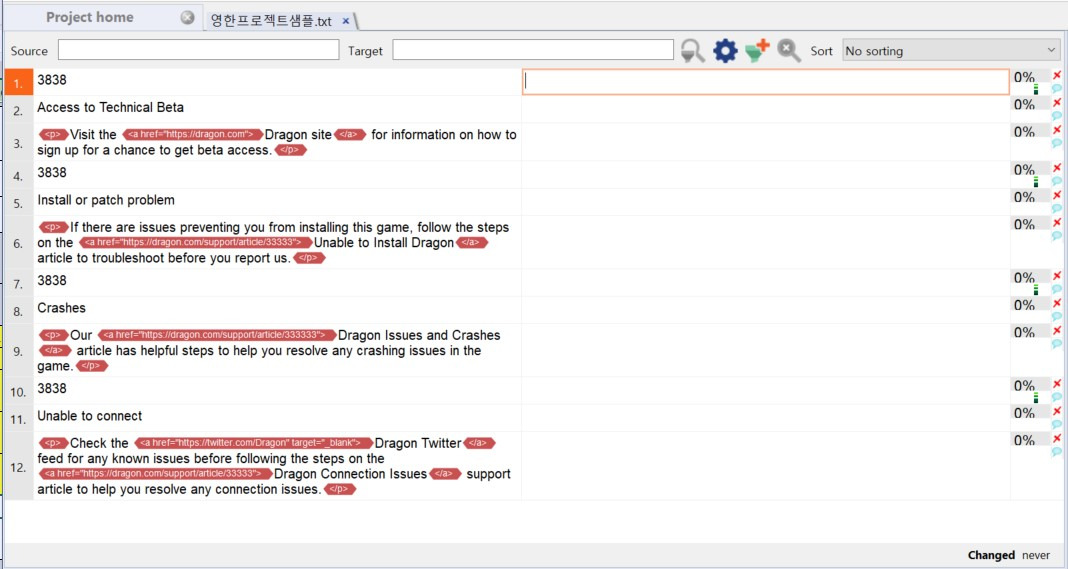
왼쪽 번역문 중 번역이 불필요한 태그 부분은 빨간색으로 표시가 되며 편집도 불가능합니다. 번역가는 이제 오른쪽 빈 칸에 번역을 하면서 왼쪽의 태그를 그대로 복사해서 사용하기만 하면 됩니다. 태그 부분이 빨간색으로 표시되면서 번역해야 할 내용의 가독성도 훨씬 좋아졌습니다.
관련 콘텐츠 함께보기
2023.07.17 - [게임] - 게임 현지화 - 게임 번역 회사의 제공 가능한 서비스는?
2023.08.22 - [게임] - 게임 현지화 관련 직업 - 게임 번역가
2023.09.08 - [게임] - 번역가 채용은 어떻게 이루어지나? - Feat 게임 번역가
2023.07.17 - [게임] - 게임 현지화 - 업계 사람들이 사용하는 전문 용어
2023.12.01 - [게임] - 게임 현지화 관련 직업 - 프로젝트 매니저(PM)
2023.12.01 - [게임] - 게임 현지화 관련 직업 - 링귀스트(Linguist)
2023.12.07 - [게임] - 게임 현지화 관련 직업 - 현지화 엔지니어, LQA 테스터, 벤더매니저
2024.04.27 - [게임] - 게임 현지화 기초: 번역 파일 준비와 빌드 전달 프로세스
2024.04.27 - [게임] - 게임 번역 견적서 작성 가이드: 로그 분석에서 친숙화까지
2024.04.27 - [게임] - 글로벌 커뮤니케이션을 위한 첫걸음: 번역 팀 구성과 운영 노하우
2024.04.27 - [게임] - 번역가 선정에서 납품까지: 게임 현지화 프로젝트 완벽 가이드
2024.04.27 - [게임] - 스타일과 일관성, 번역에서의 중요성과 검토 방법
2024.04.27 - [게임] - 게임 현지화의 마지막 퍼즐: 효과적인 음성 녹음 방법 탐색
2024.04.27 - [게임] - 게임 녹음의 미세한 차이: 자막 일치를 위한 대본 수정의 중요성
2024.04.27 - [게임] - 게임 번역의 고단함: 고객 피드백 이해와 수용 방안
2024.04.27 - [게임] - 효율적인 LQA 테스트로 게임 퀄리티 높이기
2024.04.27 - [게임] - 번역 프로젝트 완벽 마무리하기: QA, 납품, 그리고 포스트모템
2024.09.28 - [번역이야기] - 효율적인 번역 비용 절감을 위한 로그 분석 방법
2024.09.28 - [번역이야기] - 매치레이트와 TM: 번역가를 위한 필수 도구 이해하기
2024.09.28 - [번역이야기] - 번역가를 위한 필수 가이드: 캣툴 지원 파일 형식
2024.09.28 - [번역이야기] - 번역가를 위한 정규표현식 활용 가이드
2024.09.28 - [번역이야기] - memoQ로 단일 언어 프로젝트 생성 및 비번역 처리하기
2024.09.28 - [번역이야기] - memoQ의 Run QA 기능: 번역 품질을 높이는 필수 도구
2024.09.28 - [번역이야기] - 게임 번역의 새로운 패러다임: memoQ를 통한 다국어 프로젝트 관리
'번역이야기' 카테고리의 다른 글
| 게임 번역의 새로운 패러다임: memoQ를 통한 다국어 프로젝트 관리 (31) | 2024.10.06 |
|---|---|
| memoQ의 Run QA 기능: 번역 품질을 높이는 필수 도구 (25) | 2024.10.05 |
| 번역가를 위한 정규표현식 활용 가이드 (31) | 2024.10.03 |
| 번역가를 위한 필수 가이드: 캣툴 지원 파일 형식 (29) | 2024.10.02 |
| 매치레이트와 TM: 번역가를 위한 필수 도구 이해하기 (20) | 2024.10.01 |




댓글