다국어 프로젝트 생성
이번에는 한국어에서 출발하는 다국어 프로젝트를 생성해 보겠습니다. 다국어 프로젝트는 한꺼번에 각 언어별로 번역 파일을 생성할 수 있기 때문에 전체 언어를 하나의 프로젝트 안에서 관리할 수 있다는 장점이 있습니다. 다국어 프로젝트 생성용 소스 파일도 단일 언어와 마찬가지로 게임 개발사에서 실제 의뢰하는 형식을 빌어 제작한 연습용 파일입니다. 국내 모바일 게임 개발사가 다국어 번역 의뢰 시 가장 빈번하게 사용하는 xlsx 파일 형식으로 한국어에서 영어, 일본어, 중국어(간체) 번역을 진행하는 예제를 설명해 드리겠습니다.
번역용 파일 분석
이 예제에서 사용하는 다국어번역샘플.xlsx 파일은 튜토리얼, 운영 직원, 청소 직원이라는 전체 3개의 시트로 구성되어 있습니다(파일은 이 글에 첨부 파일로 첨부되어 있음). 첫 번째 시트인 [튜토리얼]은 대사를 하는 캐릭터의 이름이 B열에, 해당 대사 시의 상태(표정) 정보가 C열에, 실제 대사가 D열에 있습니다. 번역문은 각각 E열(영어), F열(중국어), G열(일본어)에 입력할 수 있습니다. 캐릭터 이름(화자 정보: B열)과 상태 정보(C열)는 번역을 진행할 때 반드시 참고해야 할 내용입니다. 번역용 파일을 제작할 때 해당 정보가 함께 표시될 수 있도록 해야 합니다.
두 번째, 운영 직원 시트에는 텍스트의 분류 기준(B열), 텍스트의 종류(C열)가 정보로 제공되고 D열에 실제 번역해야 할 내용이 있습니다. 번역문은 각각 E열(영어), F열(중국어), G열(일본어)에 입력할 수 있습니다.
세 번째, 청소 직원 시트에는 B열에 주로 청소 직원들의 성별과 대략적인 연령대를 확인할 수 있는 정보가 있습니다. C열에는 해당 대사를 사용하는 상황에 대한 정보가 있습니다. 이 시트도 다른 시트와 마찬가지로 D열에 번역할 소스 언어가 있으며 번역문은 E(영어)열, F(중국어)열, G(일본어)열에 저장하면 됩니다.
분석한 파일 정보를 기준으로 이제 다국어 프로젝트를 만들어보겠습니다.
memoQ를 실행하고 [Project] > [New Project From Template]를 선택합니다.
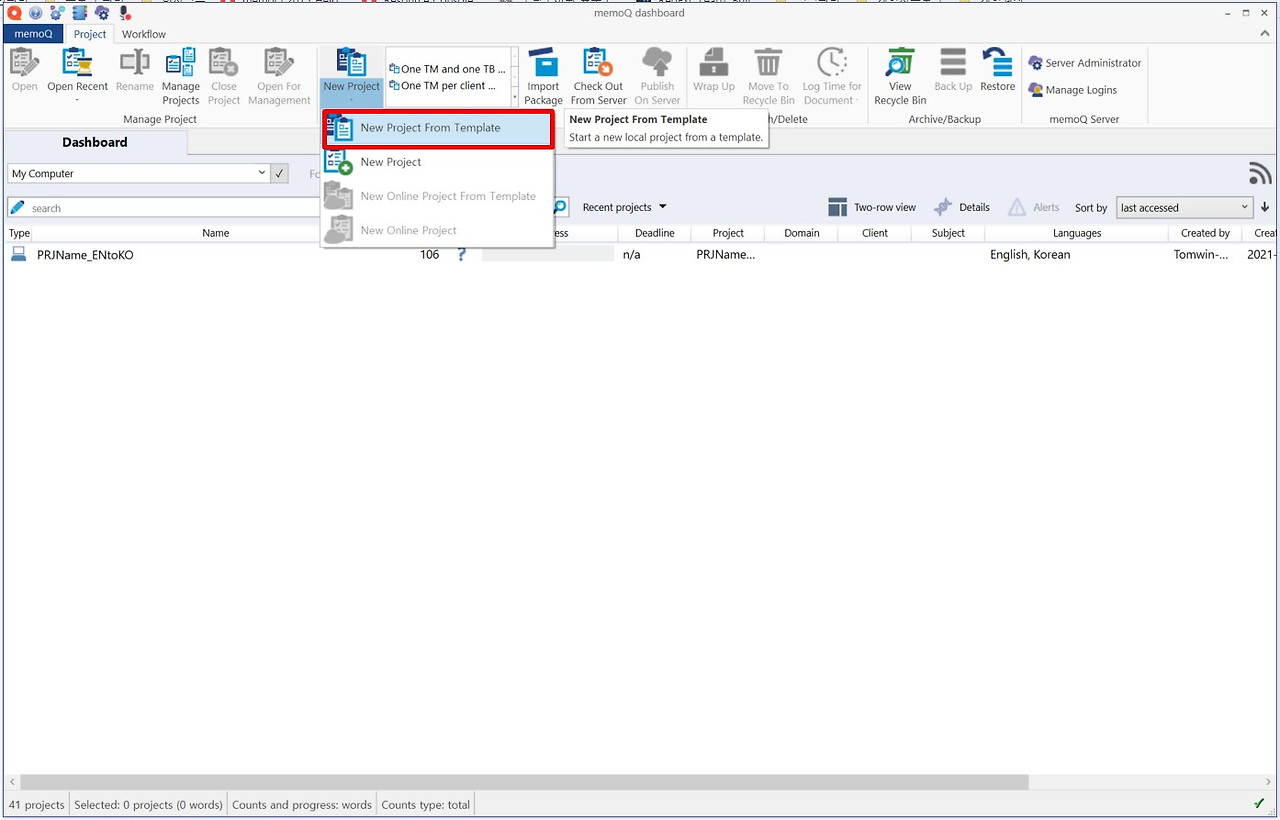
다국어 프로젝트는 단일 언어 프로젝트와 달리 memoQ에서 제공하는 템플릿을 활용합니다. 템플릿을 사용하면 몇 가지 옵션만으로도 TM, TB 등을 한꺼번에 설정할 수 있기 때문에 여러 언어를 하나의 프로젝트에 담을 때는 이 방법이 편리합니다.
현재 사용 중인 컴퓨터(로컬 컴퓨터)에 있는 소스 파일을 불러올 예정이므로 [From local computer]를 선택하고 실제 번역 파일은 프로젝트 파일 완성 후에 업로드하겠습니다. [Next]를 클릭하여 다음으로 이동합니다.
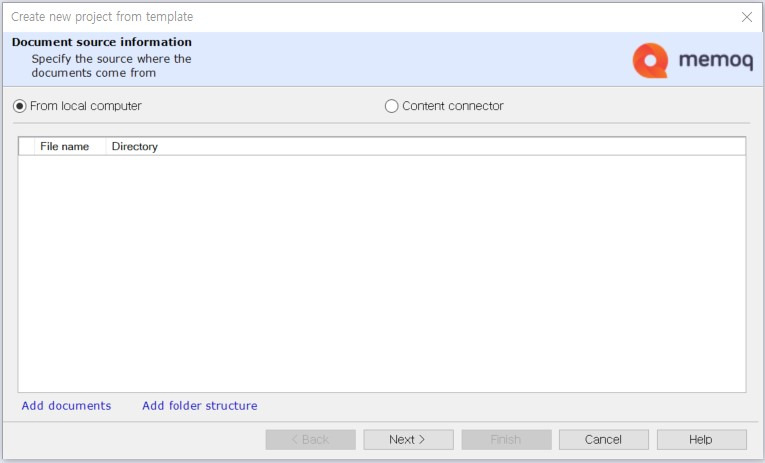
[옵션 설명]
From local computer: 번역할 소스 파일을 현재 사용 중인 컴퓨터에서 불러옵니다.
Content connector: 번역할 소스 파일이 저장된 웹 주소와 로그인 아이디를 입력하여 파일을 불러옵니다.
Add documents: 번역할 소스 파일을 파일 단위로 불러옵니다.
Add folder structure: 번역할 소스 파일을 폴더 단위로 불러옵니다.
[Project template]은 [[local] One TM and one TB per language pair (n/a -> n/a)]를 선택하여 모든 언어쌍마다 TM과 TB를 생성하도록 설정합니다. [Source language]가 [Korean]으로 설정되어 있는지 확인하고, 오른쪽 중간쯤에 있는 [Change...]를 클릭해서 [Target languages]를 영어(English), 중국어(Chinese (PRC)), 일본어(Japanese)로 설정합니다.
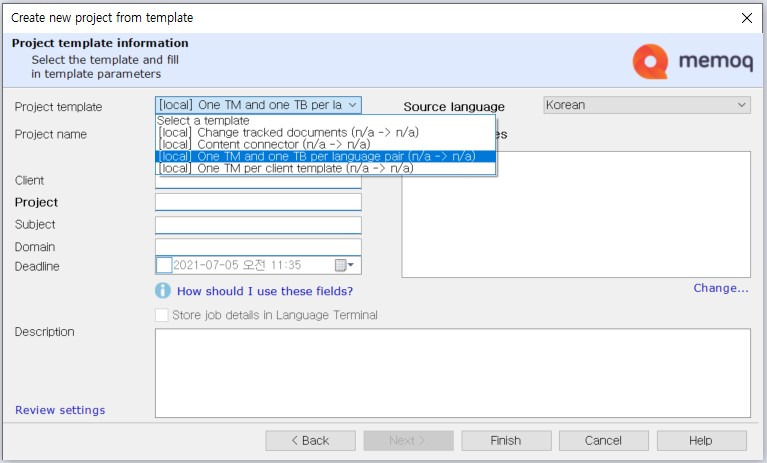
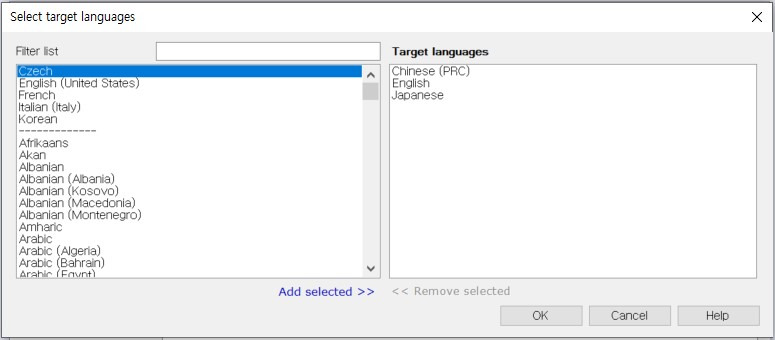
프로젝트 이름은 단일 언어 프로젝트 만들 때와 마찬가지로 누구나 알아보기 쉬운 형태로 만드는 것이 좋습니다. 권장하는 방법은 [생성날짜_고객사명_프로젝트명_언어쌍] 정도의 구조로 작성하는 것입니다. 이 예제에서는 [Sample_Project_KOto3L] 정도로만 작성하겠습니다.
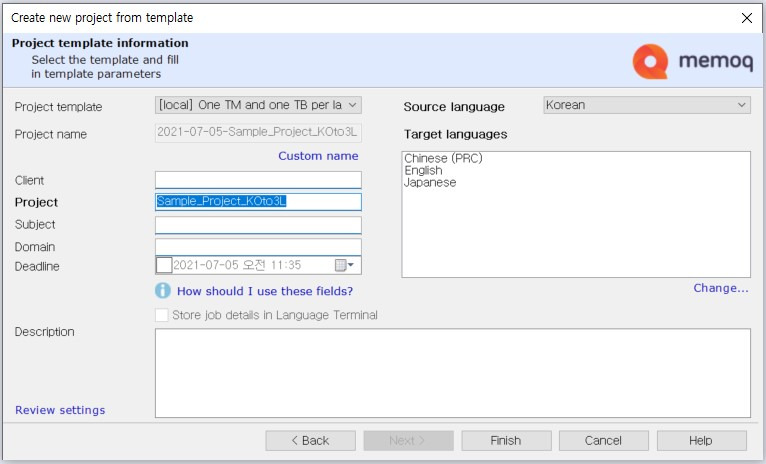
순서대로 입력을 마쳤으면 마지막으로 [Finish]를 클릭하여 다국어 프로젝트를 생성합니다. [Finish]를 클릭하면 “Your project has multiple target languages, and you naming rules will result in multiple Muses the same name. Do you wish to continue?”라는 Muse names clash 경고 메시지가 출력되는 경우가 있습니다. 여기서 말하는 Muse는 일종의 자동 추천 기능을 말합니다. 3개 언어쌍의 Muse가 동일하기 때문에 발생하는 경고이나 이후 프로젝트 설정에 큰 영향을 주는 경고문은 아니니 그대로 확인하고 다음 단계로 이동하면 됩니다.
참고: https://helpcenter.memoq.com/hc/en-us/articles/360010268100-The-Muse-as-part-of-the-immersive-editor
프로젝트가 만들어지면 아래 그림과 같이 텅 빈 Project home이 열립니다. 이제 이 화면에서 번역할 파일을 업로드해 보겠습니다.
파일을 업로드하려면 [Project home] 화면의 하얀 빈 공간에 마우스 포인터를 위치하고 마우스 오른쪽 버튼을 클릭하여 메뉴를 호출합니다. 호출된 메뉴 중 [Import with Options…]를 선택하여 업로드할 파일을 찾습니다. 업로드하는 과정에서 필요한 여러 옵션 설정은 파일의 내용을 살펴보면서 진행해야 하기 때문에 업로드할 파일을 미리 복사해 두어 내용을 참고하면서 업로드하는 것이 좋습니다.
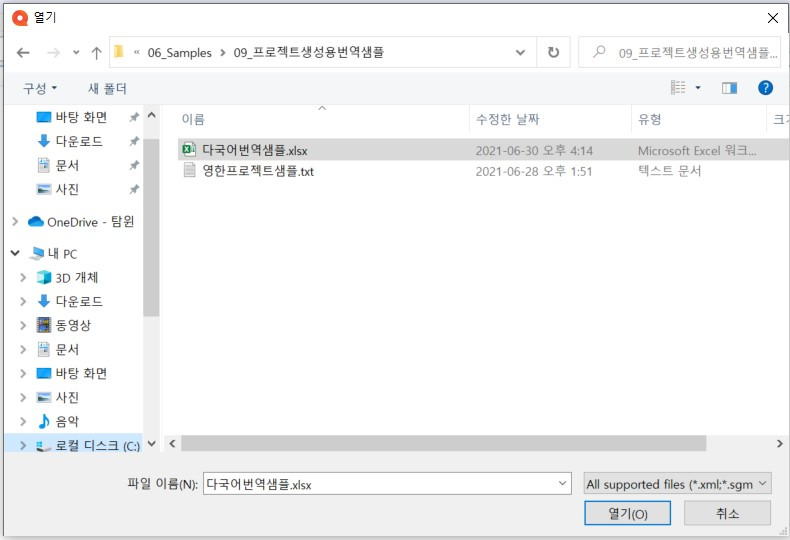
번역용 파일을 선택하고 [열기]를 클릭하면 아래 그림과 같이 필터 설정 화면이 나타납니다. 화면에 빨간색으로 표시된 부분이 필터 설정 옵션 부분입니다. 이 부분을 클릭하여 현재 필터를 [Multilingual delimited text filter]로 변경합니다. [Microsoft Excel filter]를 사용하면 소스 언어에 타겟 언어를 덮어쓰는 형식으로만 작업 진행이 가능하므로 다국어 번역을 진행할 때는 반드시 [Multilingual delimited text filter]로 옵션을 변경해서 작성해 주십시오.
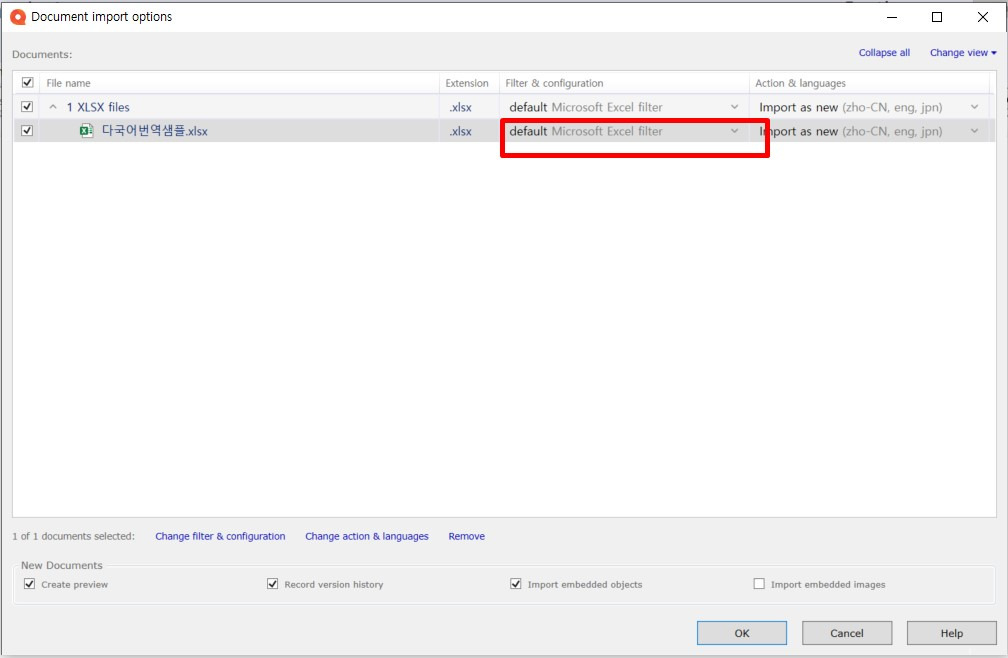
필터 변경 후에는 다음 작업을 진행하기 전에 방금 복사해 두었던 번역용 파일의 복사본을 열어둡니다. 그런 다음 [Change filter & configuration]을 클릭하여 시트별 세부 설정을 시작합니다.
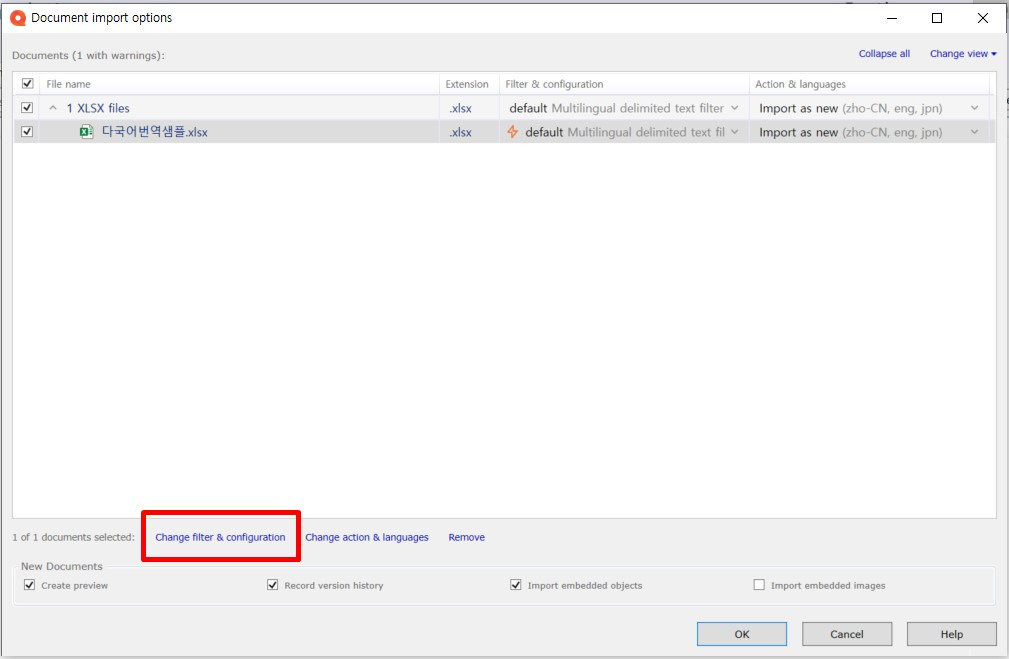
[Change filter & configuration]을 클릭하면 [Document import settings] 창이 표시됩니다. 창에는 5개의 탭이 있습니다. 여기에서 주로 사용하는 탭은 [Columns] 탭입니다. 다른 옵션은 그대로 두고 [Columns] 탭으로 이동합니다.
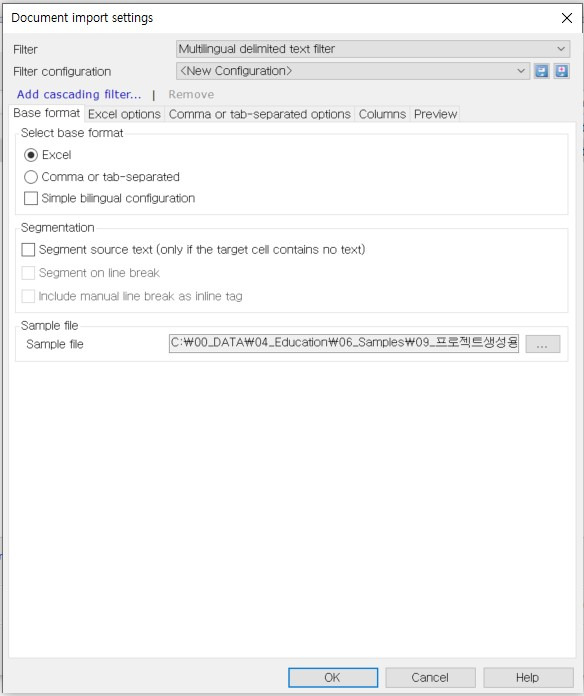
자, 이제부터는 열어 놓은 번역용 파일 복사본을 참고하면서 설정을 진행하겠습니다. 제일 먼저 복사본의 첫 번째 시트인 [튜토리얼] 시트의 내용을 확인하겠습니다. 내용이 등장하는 첫 번째 셀(3번열)은 각 열에 어떤 내용이 담겨 있는지를 알려주는 제목 역할을 합니다. 따라서 이 열은 번역 대상이 아닙니다. 이 열을 번역 대상에서 제외하려면 [Columns] 탭의 [General] 항목에서 [First row contains column names]를 선택합니다. [Source language] 항목은 한국어를 기준으로 번역할 예정이므로 [Korean]을 선택합니다. 바로 아래에 있는 [If input contains target language text]의 옵션은 기존 번역 내용이 있을 때 해당 부분을 어떻게 처리할 것인가를 선택하는 옵션입니다. 지금은 기존 번역 내용이 없으므로 기본 옵션을 그대로 사용하겠습니다.
이제 열(column)을 정의하겠습니다. [Define the meaning of columns] 창에서 [Sheet #]이 “1”로 되어 있는지 확인합니다. 여기에서 “1”은 번역용 파일의 첫 번째 시트인 [튜토리얼] 시트를 가리킵니다. 가장 먼저 지정해야 하는 것은 번역할 내용이 담긴 열입니다. 이 열을 지정해야 모든 번역의 기준점이 되어 나머지 열을 지정할 수 있습니다. 번역할 내용은 D열에 담겨 있으니 [Sheet #] 아래에 있는 창에서 D열을 선택한 다음 하단의 [Meaning of selected column] 옵션을 [Source text]로 변경합니다.
두 번째 열인 B열에는 대사를 말하는 캐릭터 즉, 화자에 대한 정보가 있습니다. B열은 대사를 번역할 때 반드시 필요한 정보이므로 [Comment]로 설정하여 번역 시 참고할 수 있도록 하겠습니다. [Sheet #] 아래에 있는 창에서 B열을 선택하고 하단의 [Meaning of selected column] 옵션을 [Comment]로 변경하고 [For column]은 방금 [Source text]로 선택했던 D열을 선택합니다.
세 번째 열인 C열에는 해당 캐릭터의 상태 정보가 담겨 있습니다. 이 부분은 [Context]로 설정하여 [Comment] 정보와 함께 번역 시 참고할 수 있게 만들겠습니다. C열을 선택하고 [Meaning of selected column] 옵션을 [Context]로 변경합니다.
이제 기본 정보 설정은 모두 마쳤습니다. 다음 해야 할 일은 번역한 내용이 저장될 열을 설정하는 것입니다. 영어 번역은 E열에 저장해야 합니다. E열을 선택하고 [Meaning of selected column] 옵션을 [Translation]으로 변경합니다. [For column]은 소스 언어가 담긴 D열을 선택하고 [Language] 옵션은 영어가 입력될 수 있도록 [English]로 변경합니다. 중국어는 F열에 저장하기로 했습니다. 영어를 저장했던 방식과 동일하게 F열을 선택하고 [Meaning of selected column] 옵션을 [Translation]으로 변경합니다. [For column]은 번역할 내용이 담긴 D열을 선택하고 [Language] 옵션은 중국어 간체가 입력될 수 있도록 [Chinese (PRC)]로 변경합니다. 마지막으로 일본어를 G열에 설정하겠습니다. G열을 선택하고 [Meaning of selected column] 옵션을 [Translation]으로 변경합니다. [For column]은 번역할 내용이 담긴 D열을 선택하고 [Language] 옵션은 일본어가 입력될 수 있도록 [Japanese)]로 변경합니다.
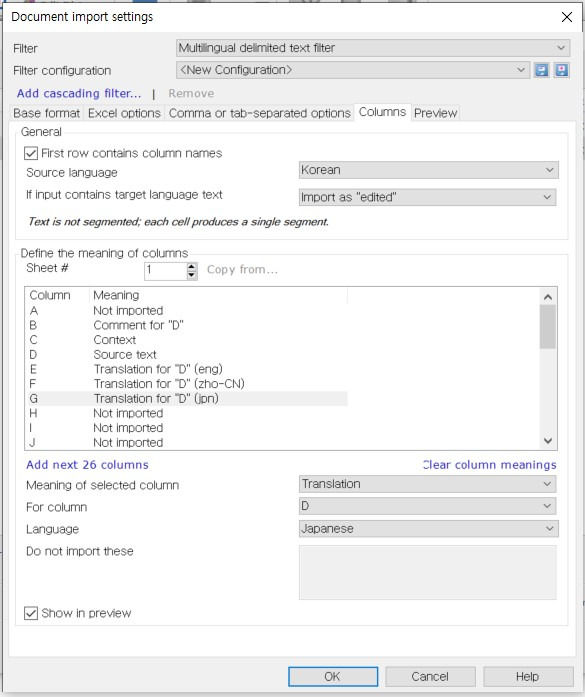
이제 첫 번째 시트에 대한 설정이 완료되었습니다. 두 번째 시트는 [Sheet #] 오른쪽에 있는 숫자 “1”을 “2”로 변경하면 설정할 수 있습니다. 당연히 “3”으로 바꾸면 세 번째 시트의 설정을 작성할 수 있습니다. 같은 방법으로 진행하면 되므로 설명은 생략하겠습니다. 2번 시트와 3번 시트의 설정을 완료하면 아래 그림과 같습니다.
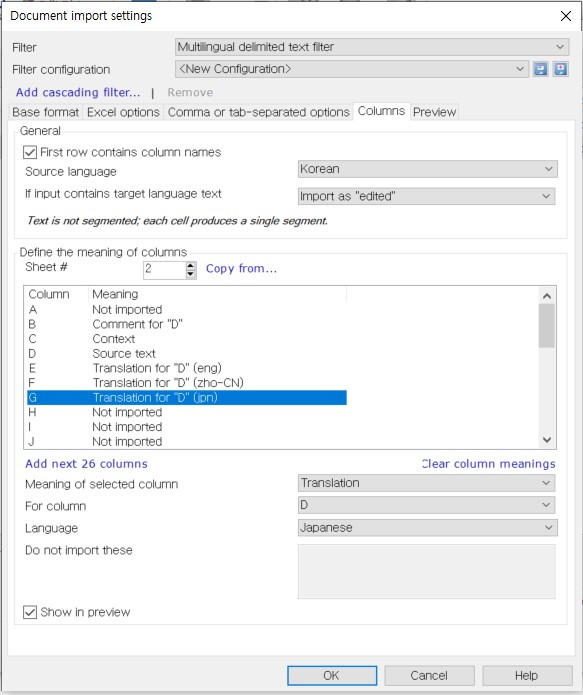
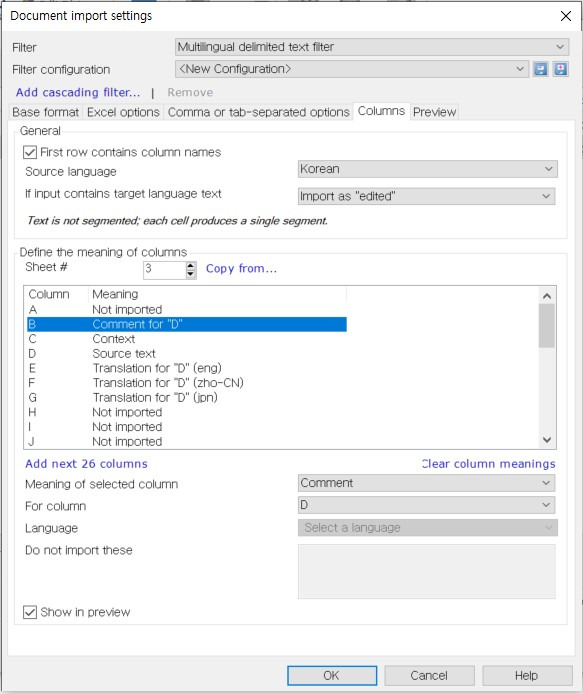
3번 시트까지 설정을 마쳤다면 [OK]를 클릭하여 [Document import options] 화면으로 돌아갑니다. 여기에서도 [OK]를 클릭하여 창을 닫으면 지금까지 설정한 내용에 따라 3개 언어의 번역 파일이 각각 자동으로 생성됩니다.
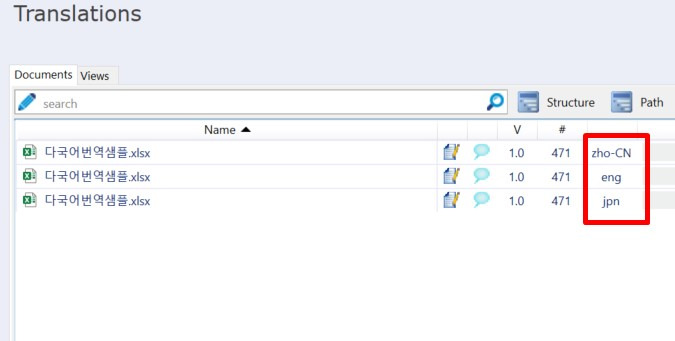
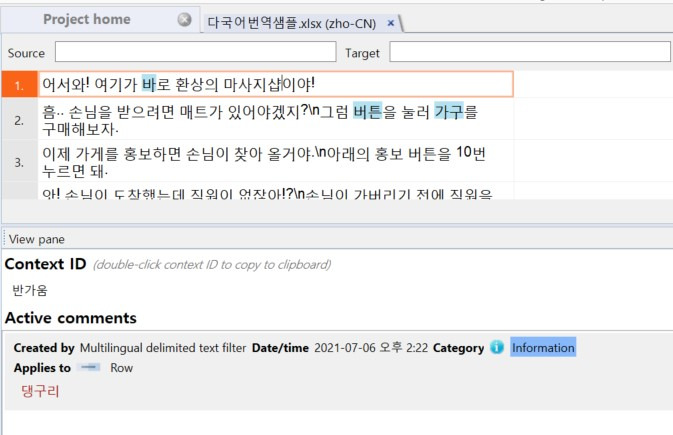
각 언어별로 생성된 파일을 열면 아래 그림과 같이 설정해 놓은 텍스트 정보를 번역문 하단에서 확인할 수 있습니다. Context ID에는 [Context]로 입력한 정보가 출력되며 Active comments에는 [Comment]로 입력한 정보가 출력됩니다.
정규표현식 필터 만들기
다국어 프로젝트에서 비번역 처리를 하는 방법도 단일 언어의 비번역 처리와 동일합니다. 자세한 내용은 단일 언어의 비번역 처리 부분을 참고해 주십시오. 여기서는 여러 개의 다국어 파일에 적용할 때마다 매번 다시 정규표현식을 입력해야 하는 번거로움을 줄일 수 있도록 정규표현식 내용을 필터로 저장하는 방법에 대해 설명해 드리겠습니다.
먼저 작성한 다국어 번역용 파일 중 하나를 열고 비번역 처리할 부분을 살펴보겠습니다. 이 파일에서는 줄바꿈 기호(\n) 외에는 비번역 처리할 내용이 없는 것 같습니다. 그럼 이 부분만 비번역 처리하는 정규표현식을 작성하겠습니다. 정규표현식은 memoQ 상단에 있는 메뉴에서 [Preparation] > [Regex Tagger]를 클릭하면 입력할 수 있습니다.
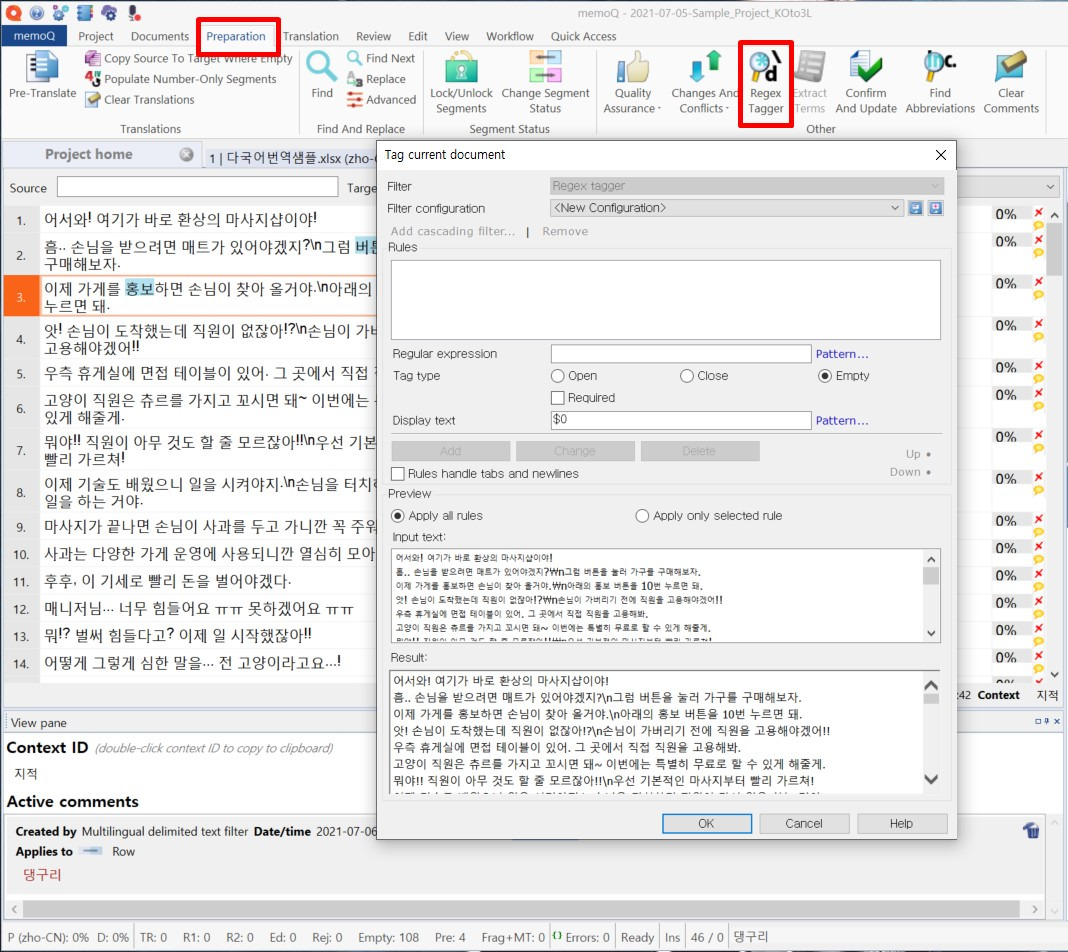
표시된 창의 [Regular expression]란에 “\n”에 해당하는 정규표현식 “\\n”을 입력하고 [Add]를 클릭합니다. 그 상태에서 창 오른쪽 상단에 있는 파란색 아이콘을 클릭하면 지금까지 입력해 놓은 정규표현식을 새로운 필터로 저장할 수 있는 창이 나타납니다. 구분하기 쉬운 이름으로 필터 이름을 지정하고, 필요하다면 해당 필터에 대한 추가 설명까지 입력하여 저장합니다.
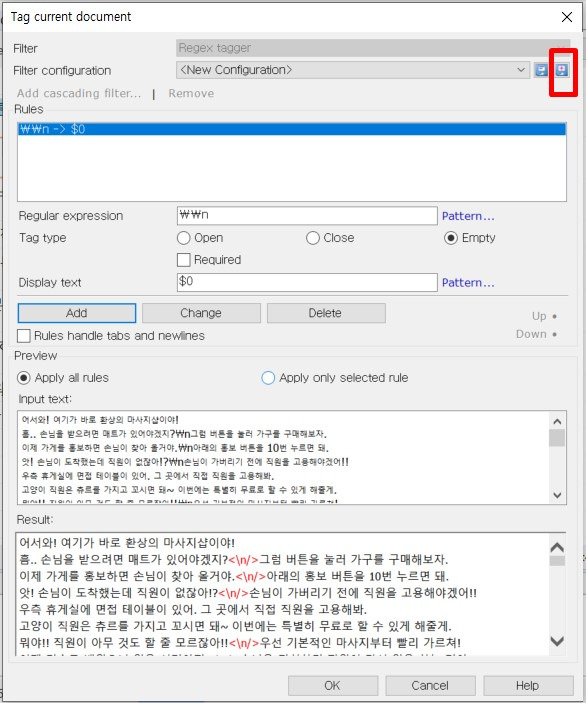
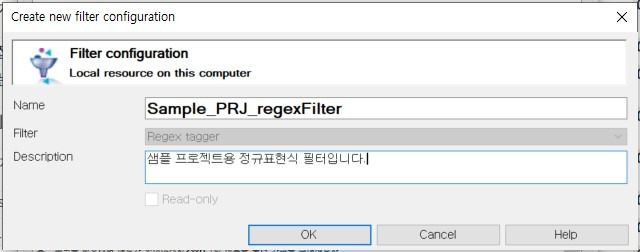
필터를 저장하고 나면 아래 그림과 같이 필터를 저장할 때 지정한 이름이 [Filter configuration] 상자에 표시됩니다. 여기까지 잘 따라오셨다면 나만의 정규표현식 필터를 만들어 저장하는 데까지 성공하신 겁니다. 이제 [OK]를 클릭하여 창을 닫아서 정규표현식이 적용된 것을 확인한 다음 해당 파일을 닫습니다.
프로젝트에 등록한 파일 중 아직 비번역 처리를 적용하지 않은 다른 파일을 엽니다. 이 예제에서는 3개 언어로 번역하면서 2개의 동일한 파일이 더 생성되었습니다. 그 중 하나를 열어서 필터를 적용하는 것으로 진행하겠습니다.
번역 파일을 연 상태에서 이전과 동일한 방식으로 [Preparation] > [Regex Tagger]를 클릭하여 창을 엽니다.
창이 열리면 [Filter configuration] 상자를 클릭하여 앞서 만들어 놓은 필터 이름을 불러옵니다. 이 예제에서는 Sample_PRJ_regexFilter라는 이름을 사용했습니다.
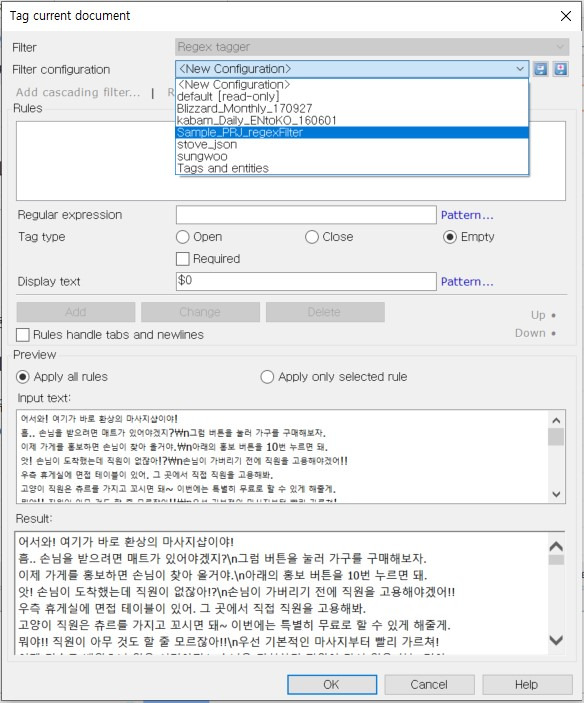
필터를 불러온 다음 [OK]를 클릭하면 이전 파일과 동일하게 비번역 처리가 완료된 파일을 확인할 수 있습니다. 정규표현식이 복잡하거나 자주 반복해서 사용하는 경우에도 이렇게 필터로 저장해 두고 사용하면 파일을 만들 때마다 다시 정규표현식을 작성해야 하는 불편을 줄일 수 있습니다.
'번역이야기' 카테고리의 다른 글
| 딥엘(DeepL) 기계 번역의 혁신: 새로운 AI 기반 언어 서비스 (7) | 2024.10.22 |
|---|---|
| memoQ의 Globalese 인수 (6) | 2024.10.21 |
| memoQ의 Run QA 기능: 번역 품질을 높이는 필수 도구 (25) | 2024.10.05 |
| memoQ로 단일 언어 프로젝트 생성 및 비번역 처리하기 (28) | 2024.10.04 |
| 번역가를 위한 정규표현식 활용 가이드 (31) | 2024.10.03 |




댓글